- ChatGPT打不开,专用网络美国海外专线光纤:老张渠道八折优惠。立即试用>
- GPT3.5普通账号:美国 IP,手工注册,独享,新手入门必备,立即购买>
- GPT-4 Plus 代充升级:正规充值,包售后联系微信:laozhangdaichong。下单后交付>
- OpenAI API Key 独享需求:小额度 GPT-4 API 有售,3.5 不限速。立即购买>
- OpenAI API Key 免费试用:搜索微信公众号:紫霞街老张,输入关键词『试用KEY』
本店稳定经营一年,价格低、服务好,售后无忧,下单后立即获得账号,自助下单 24小时发货。加V:laozhangdaichong
立即购买 ChatGPT 成品号/OpenAI API Key>>
请点击,自助下单,即时自动发卡↑↑↑
什么是OpenAI Gym中的CartPole倒立摆环境?
OpenAI Gym是一款用于研发和比较强化学习算法的工具包,其中包含多个经典控制问题的仿真环境,其中最著名的就是CartPole倒立摆环境。
定义
- 什么是OpenAI Gym?
- 什么是CartPole倒立摆环境?
- 环境特点
- 非常简单和易于理解,适合初学者入门强化学习算法的学习。
- 环境状态空间和动作空间都非常小,使得开发和测试算法的速度非常快。
- 其状态转移方程式非常规则,易于建模和求解。
OpenAI Gym是OpenAI开发的一款强化学习算法开发平台,其中包含有多个基于仿真的环境,让学习算法开发者可以更轻松地测试和比较不同的强化学习算法的性能。
CartPole倒立摆环境是OpenAI Gym中最为著名的强化学习仿真环境之一。在这个环境中,智能体需要通过控制一个位于不稳定平衡点的杆子,使其保持直立不倒。杆子的一端连接到一个可以在平面上移动的滑块上,滑块通过轮子在地面上移动。智能体的目标是最大化在给定时间内保持杆子直立的时间。
CartPole倒立摆环境的特点如下:
使用场景
- 什么是强化学习?
- 如何使用CartPole倒立摆环境进行强化学习?
- 设定强化学习任务的具体目标和奖励函数。
- 根据环境的状态空间和动作空间选择合适的强化学习算法。
- 建立智能体与环境的交互过程,在每个时间步执行如下操作:
- 根据当前状态选择一个动作。
- 执行动作并观察环境反馈的奖励。
- 根据奖励修正自己的策略。
- 重复循环以上步骤,直到达到任务目标或迭代次数。
强化学习是一种通过与环境互动学习最优行为的机器学习算法。在强化学习中,一个智能体在环境中执行一个动作,观察环境的反馈(奖励或惩罚),并据此修正自己的行为策略,让自己获得更好的长期累积奖励。
使用CartPole倒立摆环境进行强化学习,通常的步骤如下:
总之,CartPole倒立摆环境是一款优秀的强化学习仿真环境,适合初学者培养实际操作经验和开发基础算法,也吸引了很多深度学习和强化学习领域的专家研究和探索。
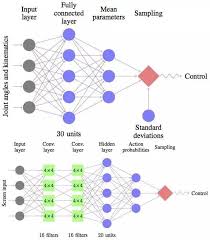
如何训练一个基于CartPole倒立摆环境的强化学习智能体?
强化学习(Reinforcement learning, RL)是机器学习的一个子领域,它通过与环境进行交互获得的奖赏指导行为,从而学习如何在该环境中获得最大化的奖赏。在强化学习中,一个智能体需要在不断试错和调整中逐步提高其性能,从而实现目标。
在本文中,我们将重点介绍如何使用强化学习算法训练一个能够在CartPole倒立摆环境中持续平衡杆子的智能体。
环境搭建
首先,我们需要搭建好CartPole倒立摆环境。而为了更加方便地创建和管理强化学习环境,OpenAI Gymnasium推出了一个叫做OpenAI Gym的强化学习开发工具包。要使用OpenAI Gym创建CartPole倒立摆环境,您需要按照以下步骤操作:
- 安装并配置OpenAI Gym。
- 创建CartPole倒立摆环境。
- 使用Python编写强化学习程序。
您可以前往OpenAI Gymnasium官网下载OpenAI Gym。安装时,您需要同时安装和配置Python,以及anaconda/miniconda环境。
在安装好OpenAI Gym之后,您可以使用以下代码创建CartPole倒立摆环境:
import gym
env = gym.make('CartPole-v0')在创建好CartPole倒立摆环境之后,我们就可以使用Python来实现强化学习程序。这里推荐使用TensorFlow、Keras、PyTorch等强化学习框架。
算法选择
常用的强化学习算法有价值函数估计算法、策略优化算法和深度强化学习算法等。针对不同的场景,我们需要选择最适合的算法。
- 当智能体目标明确,状态空间和动作空间都很小的时候,可以使用Q-learning等价值函数估计算法。
- 当状态和动作空间非常大且连续的时候,策略优化算法比较适合,如策略梯度方法。
- 深度强化学习是深度学习和强化学习相结合的产物,成为了近年来强化学习研究的热点。
模型训练
在选择好算法之后,我们需要对模型进行训练,并调整相应的超参数和学习策略。
- 设置训练过程的超参数。
- 对模型进行评估。
- 调优模型以获得最佳性能。
超参数是指在模型训练的过程中,需要手工调整的参数,包括学习率、折扣因子、探索率等。
评估模型的效果是非常重要的。我们需要考虑模型的平均回报、训练过程中的奖励曲线、测试过程中的持续时间,以及模型对异常情况的处理等。
在训练模型的过程中,我们需要不断调整超参数和训练策略,以获得最佳性能。这可以通过比较不同超参数和训练策略下模型的性能得到。
强化学习在实际场景中的应用——以CartPole倒立摆环境为例
强化学习是机器学习的一个分支,与智能控制机器人和预测分析等领域密切相关。本文将以经典的强化学习环境——CartPole倒立摆为例,探讨在实际场景中强化学习的应用与类比思维。
如何将CartPole倒立摆环境与实际场景进行类比?
- 场景类比思维: 将实际场景与CartPole倒立摆环境进行类比,找出相似之处,并将强化学习算法应用于实际场景中。
- 模型推理思维: 通过对实际场景的建模,搭建系统的数学模型,并用CartPole倒立摆环境进行模型推理,得出最优解决方案。
如何应用类比思维解决实际问题?
首先,我们需要找到实际场景中的“杆”(可以是机器人手臂、流水线工作台等),然后将其建模成CartPole倒立摆环境。接着,通过与CartPole倒立摆环境的类比思维,利用强化学习算法进行控制,从而实现系统的自主控制和优化。
如何利用CartPole倒立摆环境进行交通流控制?
在交通流控制领域,我们可以将车流量比作倒立摆的“杆”,车辆速度和路段拥堵情况则可以看作“杆”的状态和动作。此时,我们可以用强化学习算法对“杆”的位置和速度进行控制,调整车流量,从而优化交通流量。
| 状态 | 动作 | 奖励 |
|---|---|---|
| 车辆数量、速度、拥堵程度 | 调整红绿灯时长、设立单行道、限制车速等 | 减少拥堵、提高通行效率 |
| 车流量稳定、车速适中 | 保持原有措施不变 | 维持稳定水平 |
如何利用CartPole倒立摆环境进行智能制造生产线控制?
在智能制造领域,我们可以将生产线看作倒立摆的“杆”,生产效率和物料流速度则可以看作“杆”的状态和动作。此时,我们同样可以用强化学习算法对“杆”的位置和速度进行控制,优化生产效率和物料流速度。
| 状态 | 动作 | 奖励 |
|---|---|---|
| 生产线生产效率、物料流速度 | 调整生产节奏、优化工作流程、减少物料运输时间等 | 提高生产效率和物料流速度 |
| 生产线稳定、物料流畅 | 保持原有措施不变 | 维持稳定水平 |
总之,在实际场景中,我们可以通过类比思维将CartPole倒立摆环境与场景进行类比,用强化学习算法进行控制,优化系统的性能和效率。
想学习更多关于强化学习和CartPole倒立摆环境的知识吗?可以参考Python使用者必看!OpenAI API简明指南,学习如何使用OpenAI Gym进行环境搭建和算法优化。
未来展望
强化学习是一种通过让智能体在环境中进行实验和交互,从而不断学习和完善自身决策能力的机器学习技术。随着技术的不断发展,我们有理由相信强化学习在未来会有更广阔的应用前景。
强化学习的未来发展方向
- 结合深度学习方法:深度学习已经在许多领域得到广泛应用,结合强化学习算法的方法可以进一步提高算法的准确性、鲁棒性和学习效率。
- 多智能体学习:当前的强化学习系统主要是单智能体学习,未来可以借助多智能体学习技术,使智能体之间能够相互协作、竞争,从而实现更高效的学习。
- 可解释性强化学习:随着人们对于机器智能的信任度不断提高,对于强化学习算法的可解释性需求也越来越高。未来的研究可以通过解释智能体学习的过程和步骤,使得强化学习算法更具可信度。
参考链接:
OpenAI GPT-3.5 API:模型和API参考
CartPole倒立摆环境的扩展及应用前景
CartPole倒立摆环境是OpenAI Gym中经典的控制问题之一,它的特点是要求智能体通过对车身和摆杆的控制,使得摆杆保持竖直状态。未来CartPole倒立摆环境有以下扩展和应用前景:
| 扩展及应用前景 | 详情 |
|---|---|
| 增加环境难度 | 未来可以通过增加CartPole倒立摆环境的难度,如增加运动学约束、添加噪声等,来更好地训练强化学习算法。 |
| 与其他环境结合 | 未来可以通过将CartPole倒立摆环境与其他环境进行结合,如与游戏环境结合,从而开发出更加智能的游戏玩家。 |
| 应用于实际控制问题中 | 未来可以借鉴CartPole倒立摆环境的控制思想,应用于实际控制问题中,如机器人控制、自动驾驶等领域。 |

openai gym cartpole的常见问答Q&A
什么是Cart Pole(倒立摆)?
Cart Pole(倒立摆)是OpenAI Gym中的一个经典的控制问题,它是一个具有离散状态和动作空间的任务。在该问题中,有一支杆子以非固定的枢轴被连接到一个小车上,仿真过程中小车沿着无摩擦轨迹移动。任务的目标是使杆子保持直立状态。通过在杆子和小车之间施加平移力,目标是保持杆子在垂直方向以上并尽可能长时间地保持这种状态。这是一个重要的强化学习问题,旨在测试强化学习代理在平衡控制中的能力。
使用OpenAI Gym 如何训练 Cart Pole(倒立摆)?
要在Cart Pole(倒立摆)中训练强化学习代理,请按照以下步骤进行:
- 步骤1:安装Gym,使用以下命令安装:!pip install gym
- 步骤2:导入CartPole-v0环境,使用以下命令:import gym env = gym.make(“CartPole-v0”)
- 步骤3:重置环境,使用以下命令:obs = env.reset()
- 步骤4:使用循环运行游戏,并更新代理,使用以下命令:for step_index in range(max_steps): action = agent.get_action(obs) prev_obs = obs obs, reward, done, _ = env.step(action) agent.update(prev_obs, action, reward, obs, done) if done: break
- 步骤5:关闭环境,使用以下命令:env.close()
Q-Learning 如何应用于 Cart Pole(倒立摆)?
Q-Learning是一种经典的强化学习算法,非常适合Cart Pole(倒立摆)问题。Q-Learning算法的核心是Q表,它存储每个状态和行动所对应的Q值,该值表示在特定状态和行动下累积奖励的期望价值。我们可以通过在每个时间步骤中存储状态、行动、奖励和下一个状态来更新Q表,以优化代理的行为。
以下是应用Q-Learning算法解决Cart Pole(倒立摆)问题的示例代码:
import gym
import numpy as np
env = gym.make('CartPole-v1')
# 初始化Q表
buckets = (1, 1, 6, 3)
Q_table = np.zeros(buckets + (env.action_space.n,))
# 学习参数设置
alpha = 0.1
gamma = 1.0
epsilon = 0.1
# 训练Q表
successful_episodes = 0
for episode in range(10000):
observation = env.reset()
total_reward = 0
for t in range(501):
if np.random.uniform(0, 1) < epsilon:
action = env.action_space.sample()
else:
action = np.argmax(Q_table[observation])
next_observation, reward, done, info = env.step(action)
# 将状态桶化
position, velocity, angle, angular_velocity = next_observation
bucket = (
int(position * buckets[0]),
int(velocity * buckets[1]),
int(angle * buckets[2]),
int(angular_velocity * buckets[3])
)
# 更新Q表
best_q = np.amax(Q_table[bucket])
Q_table[observation + (action,)] += alpha * (reward + gamma * best_q - Q_table[observation + (action,)])
total_reward += reward
observation = bucket
if done:
if total_reward >= 195:
successful_episodes += 1
break
# 打印训练结果
if episode % 100 == 0:
success_rate = successful_episodes / 100
successful_episodes = 0
print('Episode {0} success rate: {1:.3f}.'.format(episode, success_rate))
env.close()如何使用 OpenAI Gym 进行强化学习?
OpenAI Gym是一个强化学习研究的工具包,提供了一系列标准的强化学习环境和相应的API接口,开发者可以通过它来测试和比较强化学习算法的性能。
以下是使用OpenAI Gym进行强化学习的示例代码:
import gym
env = gym.make('CartPole-v1')
def run_episode(env, policy, max_steps=1000, render=False):
obs = env.reset()
total_reward = 0
for step_index in range(max_steps):
if render:
env.render()
action = policy(obs)
obs, reward, done, _ = env.step(action)
total_reward += reward
if done:
break
return total_reward
def run_policy_search_algorithm(env, policy_search_algorithm, num_iterations=200):
policy = lambda obs: policy_search_algorithm.predict(obs)
for i in range(num_iterations):
new_policy = policy_search_algorithm.update(policy)
policy = lambda obs: new_policy.predict(obs)
reward = run_episode(env, policy)
print('Policy {0} reward: {1}'.format(i, reward))
run_policy_search_algorithm(env, your_policy_search_algorithm)OpenAI Gym 中 Cart Pole(倒立摆)相关的一些项目有哪些?
以下是一些OpenAI Gym中与Cart Pole(倒立摆)相关的项目:
- Intro to Reinforcement Learning | OpenAI Gym, RLlib & …
- Cart Pole Gym using Reinforcement Learning
- Cart Pole Control Environment in OpenAI Gym (Gymnasium)
- Using Q-Learning for OpenAI’s CartPole-v1
- OpenAI Gym Cart Pole – Colaboratory
- How to build a cartpole game using OpenAI Gym
- OpenAI Gym #1 – Reinforcement Learning for CartPole
- OpenAI Gym: CartPole-v1 – Q-Learning
- CartPole with Q-Learning – First experiences with OpenAI Gym
这些项目可以帮助开发者更好地了解和学习Cart Pole(倒立摆)问题及其解决方法。
如何使用 OpenAI Gym 进行自定义环境设计?
要在OpenAI Gym中创建自定义环境,请参考以下步骤:
- 步骤1:创建gym.Env子类,并实现必要的方法,包括__init__、reset、step和render方法。
- 步骤2:将状态和行动空间定义为Box或Discrete类。Box类表示实数空间,Discrete类表示离散空间。
- 步骤3:将环境注册到Gym环境列表中,使用以下方法:gym


